

عصر دیجیتالی که ما در آن زندگی می کنیم، شیوه کار، بازی و یادگیری ما را تغییر می دهد. برای سازمان هایی که در تلاش برای دستیابی به تحول دیجیتالی هستند، یا از طریق تجزیه و تحلیل داده ها به صورت رقابتی رفتار می کنند، داده محور شدن یک هدف کلیدی است . پیشرفت در دستیابی به این هدف بسیار کند است.
خوشبختانه، اکثر شرکت های پیشرو به سرعت تجزیه و تحلیل داده های بزرگ را در مدل های کسب و کار خود گنجانده اند. با افزایش حجم دادههای موجود برای سازمانها، کسبوکارها نیاز ضروری به استخدام دانشمندان داده پیدا میکنند.
چگونه کسب و کار خود را با استفاده از داده های تحلیلی بهبود بخشید
استفاده از تجزیه و تحلیل داده ها در ابتدا می تواند ترسناک به نظر برسد. استفاده از داده های بزرگ برای بهبود فرصت های تجاری مفهوم جدیدی نیست. وقتی به ریشههای گوگل نگاه میکنید، الگوریتم PageRank آنها موفقیت بزرگی بود که به آنها اجازه داد تا خود را به عنوان کاربرپسندترین موتور جستجوی موجود قرار دهند. تابع PageRank بهترین نتایج را با سازماندهی مقدار زیادی محتوا به کاربر ارائه می دهد. این مفهوم ساده به کلان داده ها نفوذ کرد و این آغاز یک امپراتوری شرکتی بود که همچنان بر اساس فرمول برنده ساخته می شد.
در دنیایی که به طور فزایندهای مشتری محور است، توانایی جذب و استفاده از بینش مشتری برای شکلدهی به محصولات، راهحلها و تجربه خرید در کل بسیار مهم است . با افزایش تعداد افرادی که داده ایجاد می کنند، ارزش داده های جمعی آنها نیز افزایش می یابد.
گوگل امروزی به سطوح جدیدی از پیچیدگی رسیده است: از دادهها برای آموزش مدلهای هوش مصنوعی (AI) استفاده میکند که چگونه زبانهای بسیاری را ترجمه کنند، و پروفایلهای شخصیتی مشتریان بالقوه را ایجاد میکند. هر چه داده بیشتر باشد، هوش مصنوعی بیشتر یاد می گیرد.
انفجار داده ها
از زمان شروع عصر دیجیتال، داده ها با سرعتی تصاعدی به رشد خود ادامه می دهند و نشانه های بسیار کمی از کند شدن آن وجود دارد. این هجوم مداوم داده ها به عنوان سوخت برای مدل های علم داده موجود عمل می کند و زمینه ای را برای مدل های بهبود یافته علم داده و همچنین موارد استفاده خلاقانه و جدید ایجاد می کند.
رشد اینترنت اشیا (IoT): یک دلیل بزرگ برای این انفجار داده ها اینترنت اشیا است . حدود هفت میلیارد دستگاه به اینترنت اشیا در سراسر جهان متصل هستند و پیشبینی میشود که این رقم طی هفت سال به 21.5 میلیارد برسد. انتظار میرود که خطوط هوایی، معدن و صنایع خودروسازی بزرگترین مشارکتکنندگان در دادههای اینترنت اشیا باشند و با ادامه بهبود کیفیت فناوری دستگاه، نوع دادههای جمعآوریشده غنیتر و متنوعتر میشوند.
رسانه های اجتماعی: فیس بوک تنها در مارس 2019 به طور متوسط 1.56 میلیارد کاربر فعال روزانه داشته است که در مجموع 2.38 میلیارد کاربر فعال ماهانه تا پایان آن ماه می باشد. یوتیوب گزارش می دهد که روزانه بیش از یک میلیارد ساعت ویدیو در پلتفرم خود تماشا می شود، با بیش از 1.9 میلیارد کاربر وارد شده در هر ماه. هر بار که شخصی برای مشاهده فید خبری یا تماشای ویدیوهای خود وارد سیستم می شود، داده هایی ایجاد می شود – سن، جنسیت، مکان، زبان، مدت زمان بازدیدها، انواع ویدیوهای تماشا شده، نوع محتوای مورد پسند و به اشتراک گذاشته شده، تنظیمات برگزیده کاربر و موارد دیگر. اینها دو پلتفرم برتر رسانه اجتماعی مورد استفاده در جهان هستند، اما تعداد بیشتری از آنها وجود دارد:
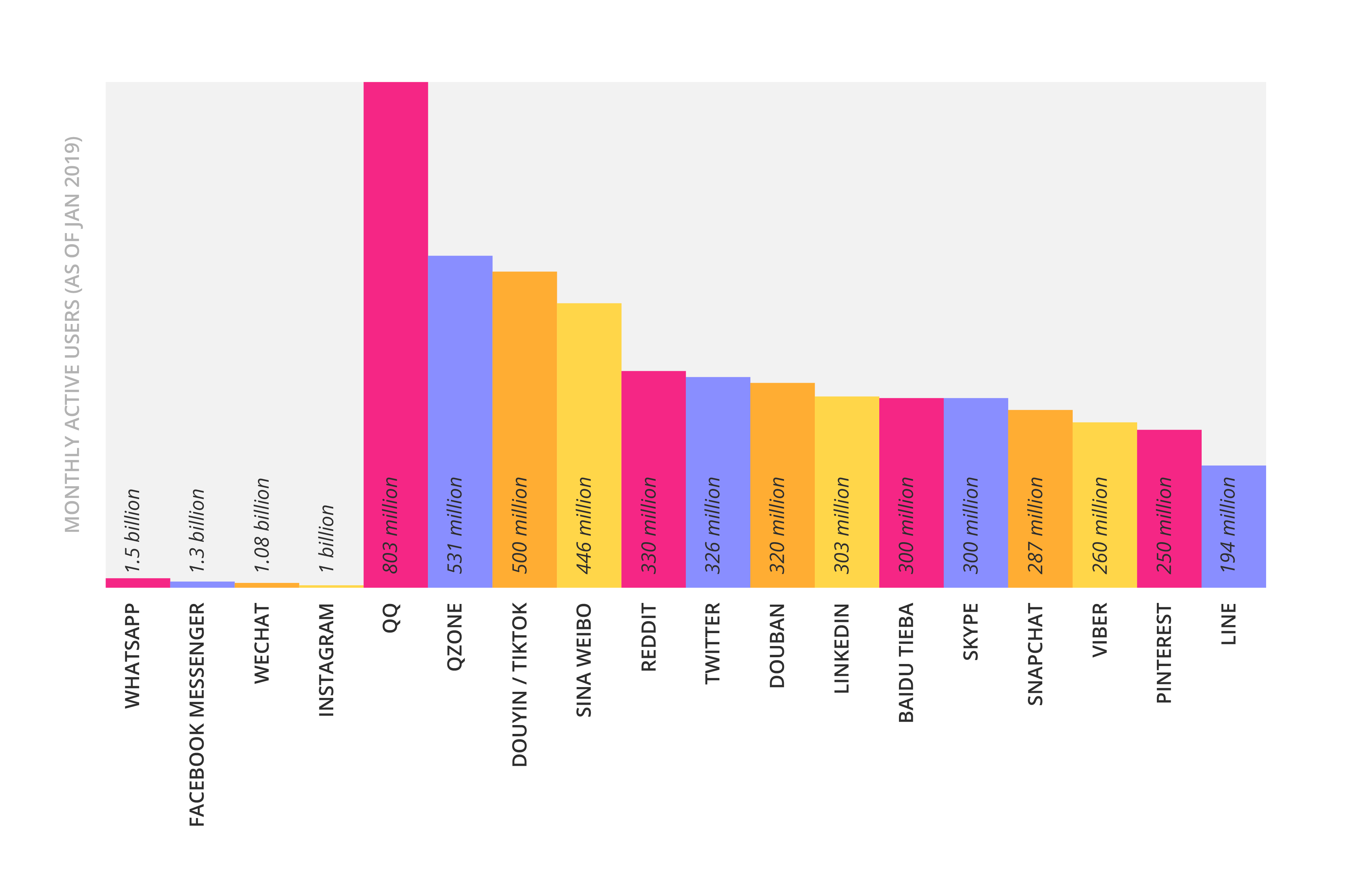
منابع داده همچنان در حال گسترش خواهند بود زیرا نیاز به جمع آوری مقادیر بیشتری از اطلاعات در مورد مشتریان افزایش می یابد. هرچه سازمانها به دادهها دسترسی بیشتری داشته باشند، مدلهای یادگیری ماشین دقیقتر خواهند شد. کاربردهای بالقوه این داده ها نیاز به علم داده را بیشتر می کند. بدون علم داده، دسترسی به ارزش کامل داده ها برای سازمان ها دشوار است.
ظهور ماشین آلات
الگوریتمهای ML در چند سال گذشته رشد سریعی داشتهاند و به همراه آن، توسعه متمرکز نرمافزار ML نیز به وجود آمده. این نرم افزار موانع ورود را برای کسانی که می خواهند دانشمند داده شوند کاهش می دهد.
تقاضا برای دانشمندان داده بیشتر از آن چیزی است که می توان عرضه کرد، بلومبرگ آن را داغ ترین شغل آمریکا در سال 2018 اعلام کرد. با این حال، اتوماسیون و آموزش علوم داده، تحقیق و تجزیه و تحلیل را بیشتر در دسترس کسب و کارها قرار می دهد. با توجه به گسترش و تسریع پذیرش علم داده و تجزیه و تحلیل در تجارت، اکثر بازیگران در زمینه علم داده، ساده سازی ابزار را در اولویت اصلی خود قرار داده اند. همراه با مجموعه ای از منابع آموزشی که متخصصان از هر زمینه را قادر می سازد تا مهارت های بسیار مورد نیاز علم داده را به دست آورند، این مهارت ها اکنون برای همه صنایع در دسترس هستند.
این پنج عامل به قرار دادن این قابلیتهای مهم در دستان متخصصان بیشتر کمک میکنند و به طور بالقوه کمبود استعداد در سراسر جهان را برطرف میکنند.
یادگیری ماشین خودکار: برخی تخمین می زنند که دانشمندان داده نزدیک به 80 درصد از روز خود را صرف کارهای تکراری می کنند که می توانند به طور کامل یا تا حدی خودکار شوند. خودکارسازی وظایفی مانند آمادهسازی دادهها، مهندسی و انتخاب ویژگی، و انتخاب و ارزیابی الگوریتم، به دانشمندان داده کمک میکند تا بهرهورتر و مؤثرتر باشند.
توسعه اپلیکیشن کم کد یا بدون کد: پلتفرمهای مختلف توسعه نرمافزار کمکد و بدون کد برای کارکنان فناوری اطلاعات و غیرفنی برای توسعه برنامههای هوش مصنوعی در دسترس هستند و میتوانند توسعه و تحویل برنامهها را تا 10 برابر سریعتر از روشهای سنتیتر، به لطف آنها، سرعت بخشند. رابط های گرافیکی کاربر، ماژول های کشیدن و رها کردن، و دیگر ساختارهای کاربر پسند.
مدل های از پیش آموزش دیده هوش مصنوعی: توسعه و آموزش ماژول های ML بخشی از دستاوردهای کلیدی دانشمندان داده است. اکنون، مدلهای از پیش آموزشدیدهشده هوش مصنوعی بهطور مؤثری تخصص ML را تولید میکنند و زمان و تلاش مورد نیاز برای آموزش را کاهش میدهند، برخی از آنها حتی میتوانند بینشهای کلیدی فوری ایجاد کنند.
تجزیه و تحلیل داده های سلف سرویس: بسیاری از تامین کنندگان هوش تجاری و تجزیه و تحلیل این امکان را برای کاربران تجاری یا غیر فنی فراهم می کنند که بدون استفاده از دانشمندان داده به بینش های مبتنی بر داده دسترسی داشته باشند. Salesforce، Adobe Analytics، Microsoft Power BI، و دیگران ابزارهای تجزیه و تحلیل سلف سرویس را برای تکمیل تجزیه و تحلیل داده ها و کشف ارائه می دهند. توانایی انجام پرس و جو و جستجوی زبان طبیعی، کشف دادههای بصری و تولید زبان طبیعی به کاربران تجاری دسترسی سریع به بینشها را میدهد و به آنها کمک میکند تا یافتههای دادهای مانند همبستگیها، استثناها، خوشهها، پیوندها و پیشبینیها را با هم مرتبط کنند.
شتاب یادگیری: در دسترس بودن دورههای آموزشی کوتاهمدت در زمینه علوم داده ، تحقیقات علم داده، ML و AI برای متخصصان با پیشزمینههای پایه ریاضی و کدنویسی، یادگیری در تجارت را تسریع میکند. این دوره ها روند یادگیری مهارت های پایه علم داده توسط متخصصان را سرعت می بخشد .
ابر و شبکه های عصبی
توسعه رایانههای قویتر که مقادیر بیشتری داده را پردازش و ذخیره میکنند، در ارتباط با الگوریتمهای ML، نیاز به تغییر در پردازش شبکههای عصبی آموزشی را ایجاد کرده است. از لحاظ تاریخی، آموزش شبکههای عصبی با واحدهای پردازش مرکزی (CPU) انجام میشد، اما در سال 2017 گوگل واحدهای پردازش تنسور (TPU) را سریعتر و قدرتمندتر از CPUها منتشر کرد. TPUهای ابری Google، ML را که پشت Google Translate، Photos، Search، Assistant و Gmail قرار دارد، در دسترس کسبوکارها قرار میدهد تا تلاشهای دانشمندان داده خود را برای دستیابی به پیشرفتهای تجاری تکمیل کنند.
نیاز به در دسترس بودن دادههای تمیز و قابل اعتماد به منظور ایجاد بینش تجاری معنادار به این معنی است که برای کسبوکارهایی که به دنبال مزیت هستند، علم داده مجموعهای از مهارتها است که ارزش طلا را دارد. با تقویت یادگیری ماشین، هوش مصنوعی و شبکه های عصبی مبتنی بر ابر، علم داده تا زمان نیاز به بینش مشتری محور و داده های مشتری محور که می تواند سود ایجاد کند، مورد تقاضا خواهد بود.
آیا تمایل به آشنایی با موقعیت شغلی مهندس داده دارید؟اکنون بیاموزید.
آیا تمایل به آشنایی با موقعیت شغلی دانشمند داده دارید؟اکنون بیاموزید.
آیا تمایل به آشنایی با موقعیت شغلی تحلیلگر داده دارید؟اکنون بیاموزید.




